OpenTelemetry provides a component called OpenTelemetry Collector, which can be used to collect data from multiple sources. Prometheus is a popular metrics monitoring tool that has a wide adoption. If you’re using Prometheus SDKs to generate metrics, you can collect them via OpenTelemetry collector and send them to a backend of your choice.

In this tutorial, you will configure an OpenTelemetry Collector to scrape Prometheus metrics from a sample Flask application and send it to SigNoz for monitoring and visualization.
We cover:
- What is Prometheus?
- What is OpenTelemetry
- What is OpenTelemetry Collector?
- How does OpenTelemetry Collector collect data?
- Flask Metrics that you can collect with OpenTelemetry in Prometheus format
- Collecting Prometheus Metrics with OpenTelemetry Collector
- Prerequisites
- Set up the Flask application
- Set up SigNoz
- Set up OpenTelemetry Collector
- Monitor Prometheus Metrics in SigNoz
- Conclusion
- Further Reading
If you want to jump straight into implementation, start with this prerequisites section.
What is Prometheus?
Prometheus is an open-source metrics monitoring tool. It collects and stores metrics as time-series data (metrics that change over time).
What are metrics?
Metrics are measurements taken from an application or IT infrastructure that change over time. Examples could be error responses, service requests, response latency, CPU usage, memory usage, etc.
Prometheus is a great fit for generating and collecting time-series data, but it is limited to metrics. Whereas OpenTelemetry can help generate logs, metrics, and traces, providing a one-stop solution of all your observability data needs.
What is OpenTelemetry
OpenTelemetry is a set of APIs, SDKs, libraries, and integrations that aims to standardize the generation, collection, and management of telemetry data(logs, metrics, and traces).
OpenTelemetry provides a unified and vendor-agnostic way of collecting telemetry data. Telemetry data has become critical in observing the state of distributed systems. With microservices and polyglot architectures, there was a need to have a global standard. OpenTelemetry aims to fill that space and is doing a great job at it thus far.
In comparison to Prometheus, OpenTelemetry extends beyond the sole collection of metrics, offering a more comprehensive approach to observability. Using Prometheus to collect metrics from your application involves instrumenting applications with the Prometheus SDK and deploying a Prometheus agent to collect, aggregate, and make these metrics available for monitoring and analysis. But instead of a Prometheus agent, you can use OpenTelemetry Collector to scrape Prometheus metrics. OpenTelemetry collector is more advanced and can help you collect logs and traces, too. You can also process the collected data and send it to any backend of your choice that supports OpenTelemetry data.
What is OpenTelemetry Collector?
OpenTelemetry Collector is a stand-alone service provided by OpenTelemetry. It can be used as a telemetry-processing system with a lot of flexible configurations that gather and process observability data, such as traces, metrics, and logs, from different parts of a software system. It then sends this data to chosen destinations, allowing for centralized analysis and monitoring. The collector simplifies the task of collecting and exporting telemetry data in cloud-native environments.
How does OpenTelemetry Collector collect data?
Data collection in OpenTelemetry Collector is facilitated through receivers. Receivers are configured via YAML under the top-level receivers tag. To ensure a valid configuration, at least one receiver must be enabled.
Below is an example of an otlp receiver:
receivers:
otlp:
protocols:
grpc:
http:
The OTLP receiver accepts data through gRPC or HTTP in the OTLP format. There are advanced configurations that you can enable via the YAML file.
Here’s a sample configuration for an OTLP receiver:
receivers:
otlp:
protocols:
http:
endpoint: "localhost:4318"
cors:
allowed_origins:
- http://test.com
# Origins can have wildcards with *, use * by itself to match any origin.
- https://*.example.com
allowed_headers:
- Example-Header
max_age: 7200
You can find more details on advanced configurations here.
Once a receiver is configured, it needs to be enabled to start the data flow. This involves setting up pipelines within a service. A pipeline acts as a streamlined pathway for data, outlining how it should be processed and where it should go. A pipeline comprises of the following:
- Receivers: These are entry points for data into the OpenTelemetry Collector, responsible for collecting data from various sources and feeding it into the pipeline.
- Processors: After data is received, processors manipulate, filter, or enhance the data as needed before it proceeds further in the pipeline. They provide a way to customize the data according to specific requirements.
- Exporters: After processing, the data is ready for export. Exporters define the destination for the data, whether it's an external monitoring system, storage, or another service. They format the data appropriately for the chosen output.
Below is an example pipeline configuration:
service:
pipelines:
metrics:
receivers: [otlp, prometheus]
processors: [batch]
exporters: [otlp, prometheus]
Here’s a breakdown of the above metrics pipeline:
- Receivers: This pipeline is configured to receive metrics data from two sources: OTLP and Prometheus. The
otlpreceiver collects metrics using both gRPC and HTTP protocols, while theprometheusreceiver gathers metrics from Prometheus. - Processors: Metrics data is processed using the
batchprocessor. This processor likely batches metrics before exporting them, optimizing the data flow. - Exporters: Metrics processed through this pipeline can be exported to both OTLP and Prometheus destinations. The
otlpexporter sends data to an endpoint specified in the configuration, and theprometheusexporter handles the export of metrics to a Prometheus-compatible destination.
Flask Metrics that you can collect with OpenTelemetry in Prometheus format
Monitoring metrics from your Flask applications is crucial for gaining insights into the performance, health, and behavior of your Flask application. In this section, we will look at some Flask metrics and their significance.
Metrics
Below are some of the metrics that can be collected or monitored from your Flask applications in Prometheus format.
| Metric | Description | Metric Name |
|---|---|---|
| HTTP request duration | Measures the number of HTTP requests hitting your Flask application, providing insights into request latency. | flask_http_request_duration_seconds_count |
| HTTP request sum | Tracks the total time spent processing all HTTP requests, giving an aggregate measure of the server's workload. | flask_http_request_duration_seconds_sum |
| HTTP requests total | Designed to analyze the distribution of request durations by categorizing them into specific time ranges or buckets. Useful for identifying performance outliers and understanding the spread of request durations. | flask_http_request_duration_seconds_bucket |
You can find more information here on the type of Flask metrics in Prometheus format that can be collected.
Collecting Prometheus Metrics with OpenTelemetry Collector
In this section, you will set up the OpenTelemetry collector to collect metrics from a Flask application in Prometheus format and send the collected data to SigNoz for monitoring and visualization.
Prerequisites
- Python and Flask installed
- A SigNoz cloud account
Set up the Flask application
A simple Flask application has been provided, you can access it here. The provided Flask application has been configured to export metrics in Prometheus format using the “prometheus_flask_exporter” library.
Sample Flask ApplicationAssuming you already have a Flask application to use, be sure to integrate the Prometheus metrics exporting capabilities for your application using the “prometheus_flask_exporter” library.
from prometheus_flask_exporter import PrometheusMetrics
app = Flask(__name__)
PrometheusMetrics(app)
Set up SigNoz
You need a backend to which you can send the collected data for monitoring and visualization. SigNoz is an OpenTelemetry-native APM that is well-suited for visualizing OpenTelemetry data.
SigNoz cloud is the easiest way to run SigNoz. You can sign up here for a free account and get 30 days of unlimited access to all features.
You can also install and self-host SigNoz yourself. Check out the docs for installing self-host SigNoz.
Set up OpenTelemetry Collector
The OpenTelemetry Collector offers various deployment options to suit different environments and preferences. It can be deployed using Docker, Kubernetes, Nomad, or directly on Linux systems. You can find all the installation options here. For the purpose of this article, the OpenTelemetry Collector will be installed manually.
Download the OpenTelemetry Collector
Download the appropriate binary package for your Linux or macOS distribution from the OpenTelemetry Collector releases page. We are using the latest version available at the time of writing this tutorial.
curl --proto '=https' --tlsv1.2 -fOL https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v0.89.0/otelcol-contrib_0.89.0_darwin_arm64.tar.gz
For macOS users, download the binary package specific to your system.
| Build | Architecture |
|---|---|
| M1 Chip | arm64 |
| Intel | amd64 (x86-64) |
Extract the package
Create a new directory named otelcol-contrib and then extract the contents of the otelcol-contrib_0.89.0_darwin_arm64.tar.gz archive into this newly created directory with the following command:
mkdir otelcol-contrib && cd otelcol-contrib
Extract the contents of the binary package in that directory:
tar xvzf otelcol-contrib_0.89.0_darwin_arm64.tar.gz -C otelcol-contrib
Set up the Configuration file
In the same otelcol-contrib directory, create a config.yaml file:
touch config.yaml
Paste the below config into the file:
receivers:
otlp:
protocols:
grpc: {}
http: {}
prometheus:
config:
global:
scrape_interval: 15s # Adjust this interval as needed
scrape_configs:
- job_name: 'flask'
static_configs:
- targets: ['127.0.0.1:5000'] # Adjust the Prometheus address and port
processors:
batch:
send_batch_size: 1000
timeout: 10s
exporters:
otlp:
endpoint: "ingest.{region}.signoz.cloud:443"
tls:
insecure: false
timeout: 20s # Adjust the timeout value as needed
headers:
"signoz-ingestion-key": "<SIGNOZ_INGESTION_KEY>"
logging:
verbosity: detailed
service:
telemetry:
metrics:
address: localhost:8888
pipelines:
metrics:
receivers: [otlp, prometheus]
processors: [batch]
exporters: [otlp]
Replace {region} with the region for your SigNoz cloud account and <SIGNOZ_INGESTION_KEY> with the ingestion key for your account. You can find these settings in the SigNoz dashboard under Settings > Ingestion Settings.
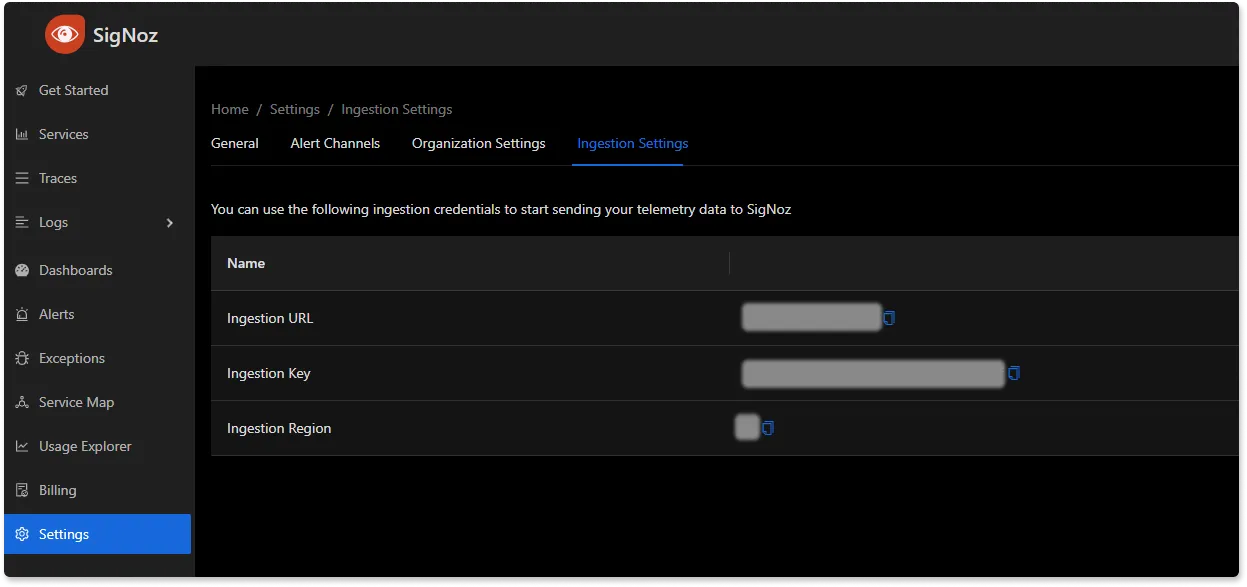
You can find more information on Prometheus receiver here.
Run the collector service
In the same otelcol-contrib directory, run the below command to start the collector service:
./otelcol-contrib --config ./config.yaml
You should receive a similar output to show it has started successfully:
2023-11-21T04:15:51.002+0100 info service@v0.89.0/telemetry.go:85 Setting up own telemetry...
2023-11-21T04:15:51.004+0100 info service@v0.89.0/telemetry.go:202 Serving Prometheus metrics {"address": "localhost:8888", "level": "Basic"}
2023-11-21T04:15:51.005+0100 info service@v0.89.0/service.go:143 Starting otelcol-contrib... {"Version": "0.89.0", "NumCPU": 12}
2023-11-21T04:15:51.005+0100 info extensions/extensions.go:34 Starting extensions...
2023-11-21T04:15:51.010+0100 warn internal@v0.89.0/warning.go:40 Using the 0.0.0.0 address exposes this server to every network interface, which may facilitate Denial of Service attacks {"kind": "receiver", "name": "otlp", "data_type": "metrics", "documentation": "https://github.com/open-telemetry/opentelemetry-collector/blob/main/docs/security-best-practices.md#safeguards-against-denial-of-service-attacks"}
2023-11-21T04:15:51.011+0100 info otlpreceiver@v0.89.0/otlp.go:83 Starting GRPC server {"kind": "receiver", "name": "otlp", "data_type": "metrics", "endpoint": "0.0.0.0:4317"}
2023-11-21T04:15:51.012+0100 warn internal@v0.89.0/warning.go:40 Using the 0.0.0.0 address exposes this server to every network interface, which may facilitate Denial of Service attacks {"kind": "receiver", "name": "otlp", "data_type": "metrics", "documentation": "https://github.com/open-telemetry/opentelemetry-collector/blob/main/docs/security-best-practices.md#safeguards-against-denial-of-service-attacks"}
2023-11-21T04:15:51.012+0100 info otlpreceiver@v0.89.0/otlp.go:101 Starting HTTP server {"kind": "receiver", "name": "otlp", "data_type": "metrics", "endpoint": "0.0.0.0:4318"}
2023-11-21T04:15:51.013+0100 info prometheusreceiver@v0.89.0/metrics_receiver.go:239 Starting discovery manager {"kind": "receiver", "name": "prometheus", "data_type": "metrics"}
2023-11-21T04:15:51.072+0100 info prometheusreceiver@v0.89.0/metrics_receiver.go:230 Scrape job added {"kind": "receiver", "name": "prometheus", "data_type": "metrics", "jobName": "prometheus"}
2023-11-21T04:15:51.072+0100 info service@v0.89.0/service.go:169 Everything is ready. Begin running and processing data.
2023-11-21T04:15:51.072+0100 info prometheusreceiver@v0.89.0/metrics_receiver.go:281 Starting scrape manager {"kind": "receiver", "name": "prometheus", "data_type": "metrics"}
Monitor Prometheus Metrics in SigNoz
Once the collector service has been started successfully, navigate to your SigNoz Cloud account and access the "Dashboard" tab. Click on the “New Dashboard” button to create a new dashboard.
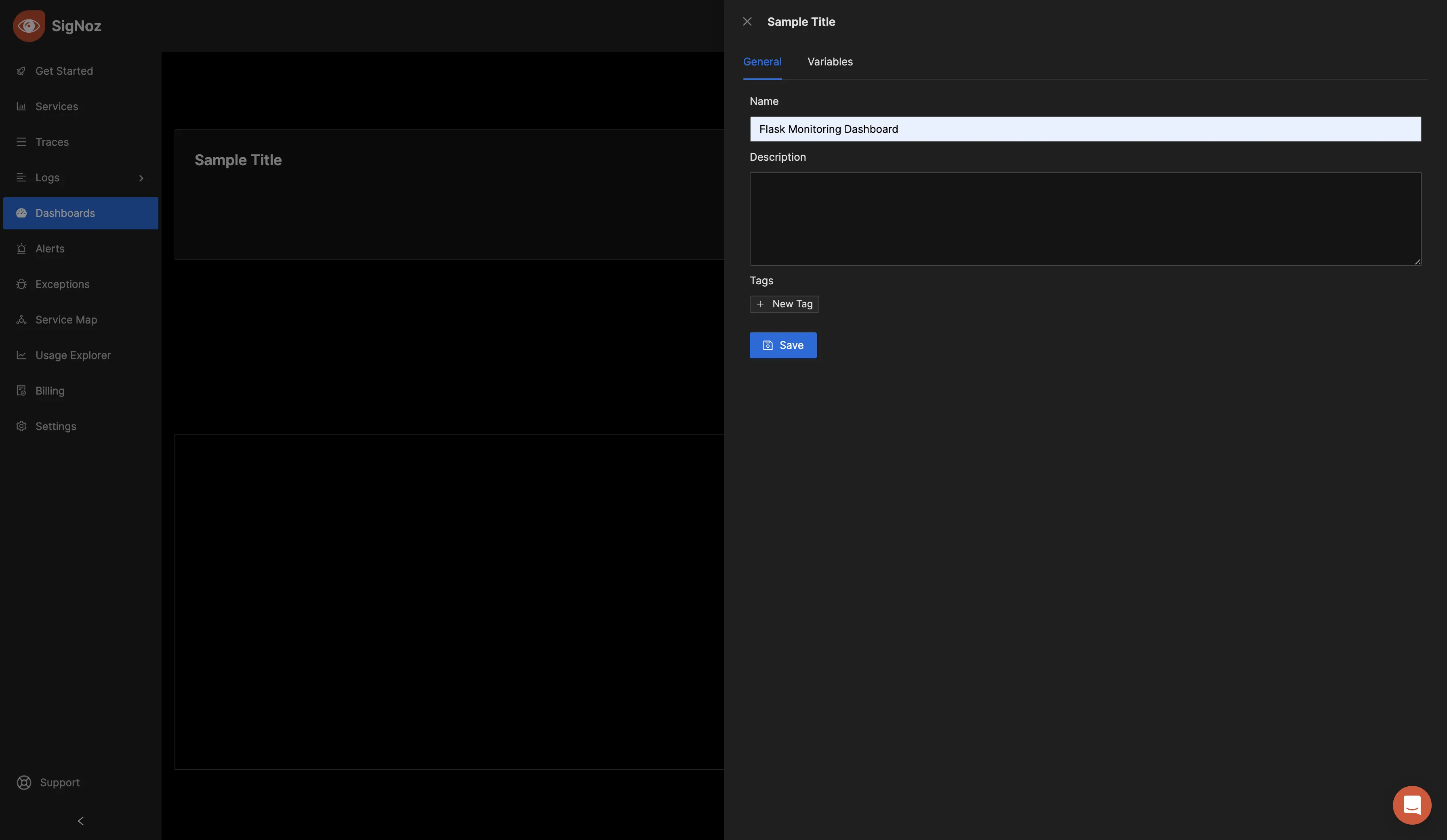
To give the dashboard a name, click on “Configure.”

Enter your preferred name in the "Name" input box and save the changes.
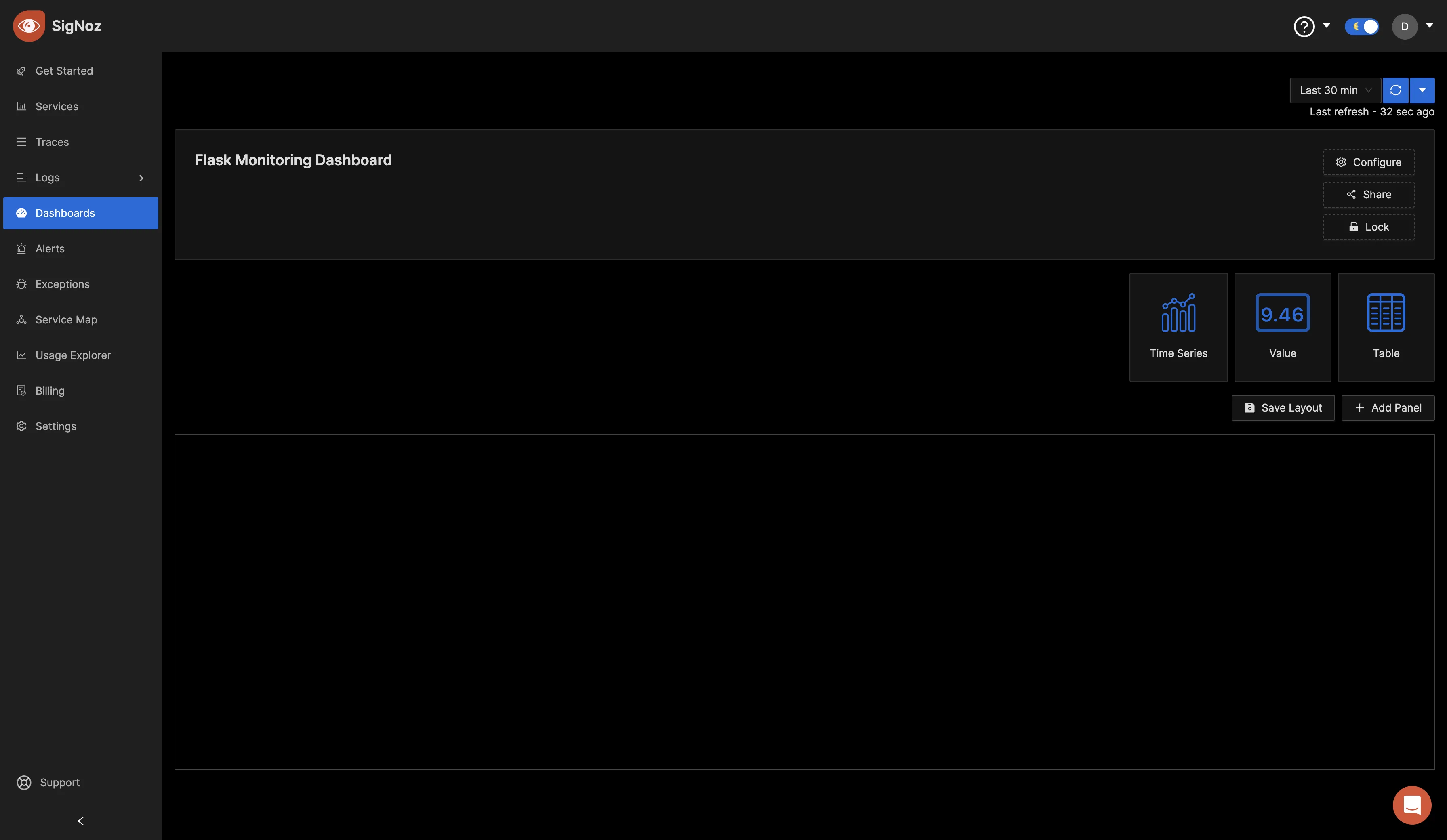
Now, you can create various panels for your dashboard. There are three visualization options to display your data: Time Series, Value, and Table formats. Choose the format that best suits your preferences, depending on the metric you want to monitor. For the initial metric, opt for the "Time Series" visualization.
In the "Query Builder" tab, enter "flask," and you should see various Flask metrics. This confirms that the OpenTelemetry Collector is successfully collecting the Flask metrics and forwarding them to SigNoz for monitoring and visualization.
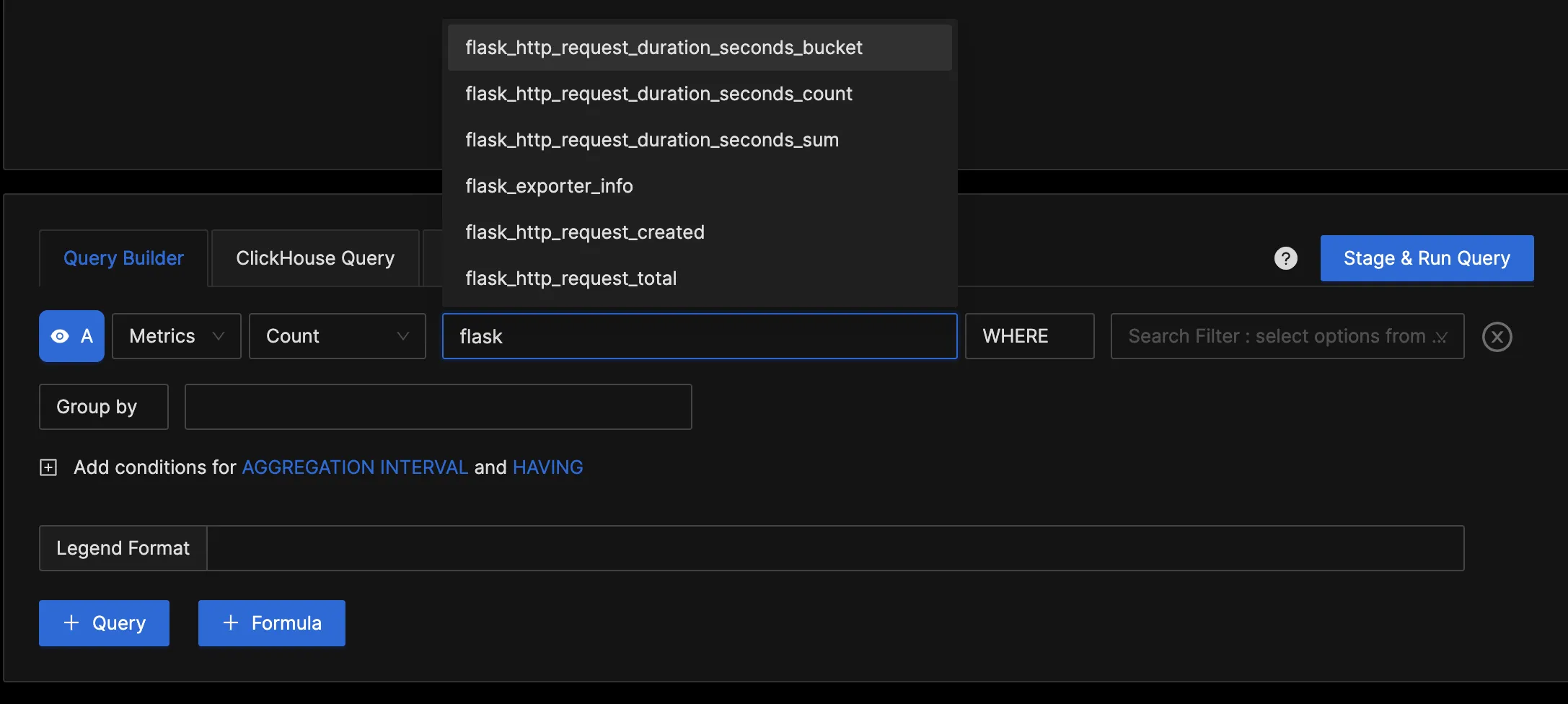
Using the Query Builder, you can run queries against your metrics. For the first query, set the below values in the Query Builder:
Telemetry data: Metrics
Aggregation: Rate
Query: flask_http_request_duration_seconds_count
Filter: status=200
It should look as the below image:
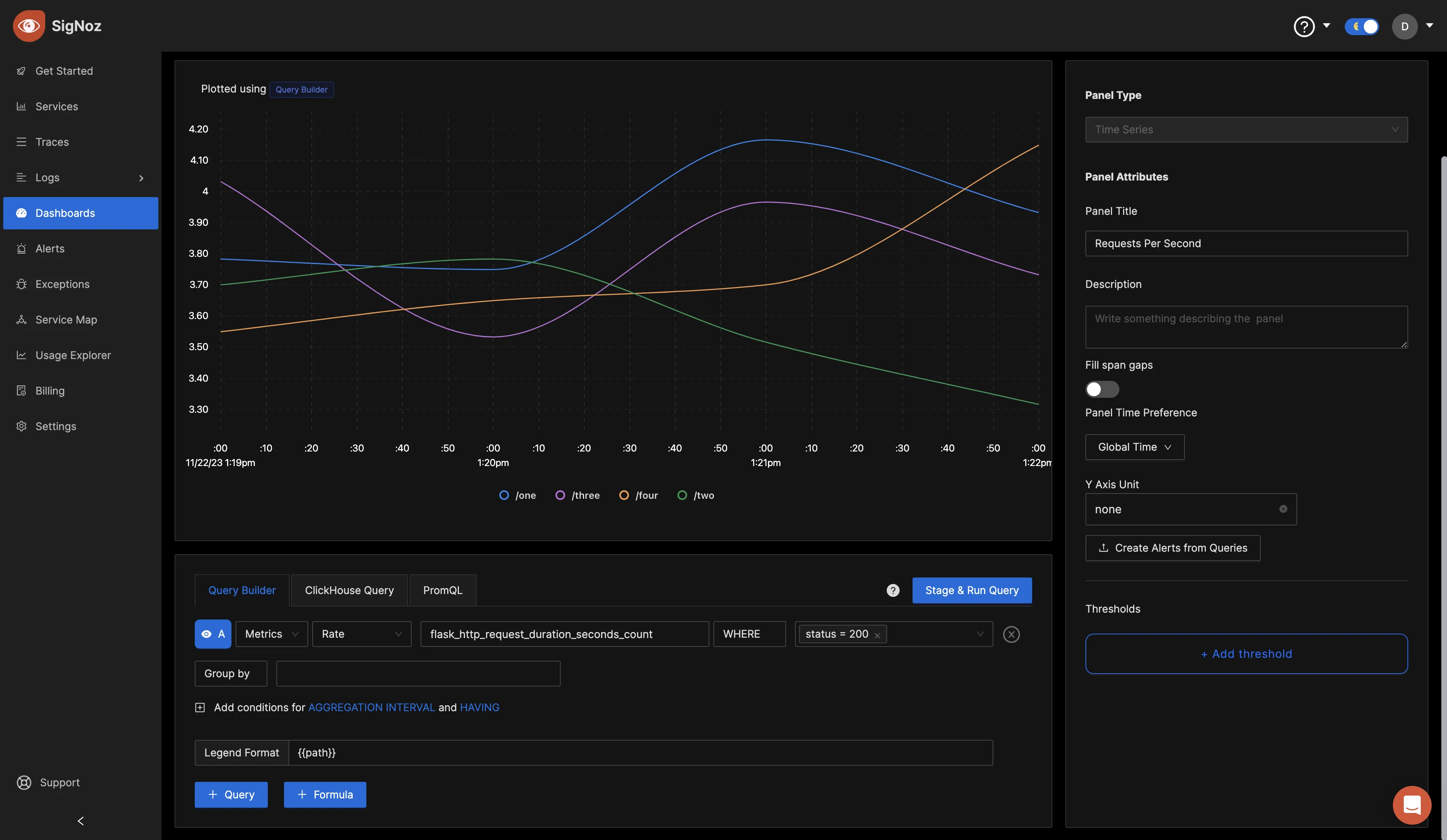
Click on the “Stage and Run Query” button to run the query, navigate up, and you will find the "Save" button to save your changes.
You can also query metrics using PromQL. Add a new panel and switch over to the PromQL tab. Set the below values in PromQL:
PromQL Query: histogram_quantile(0.9, rate(flask_http_request_duration_seconds_bucket{status="200"}[30s]))
Legend Format: {{path}}
It should look as the below image:
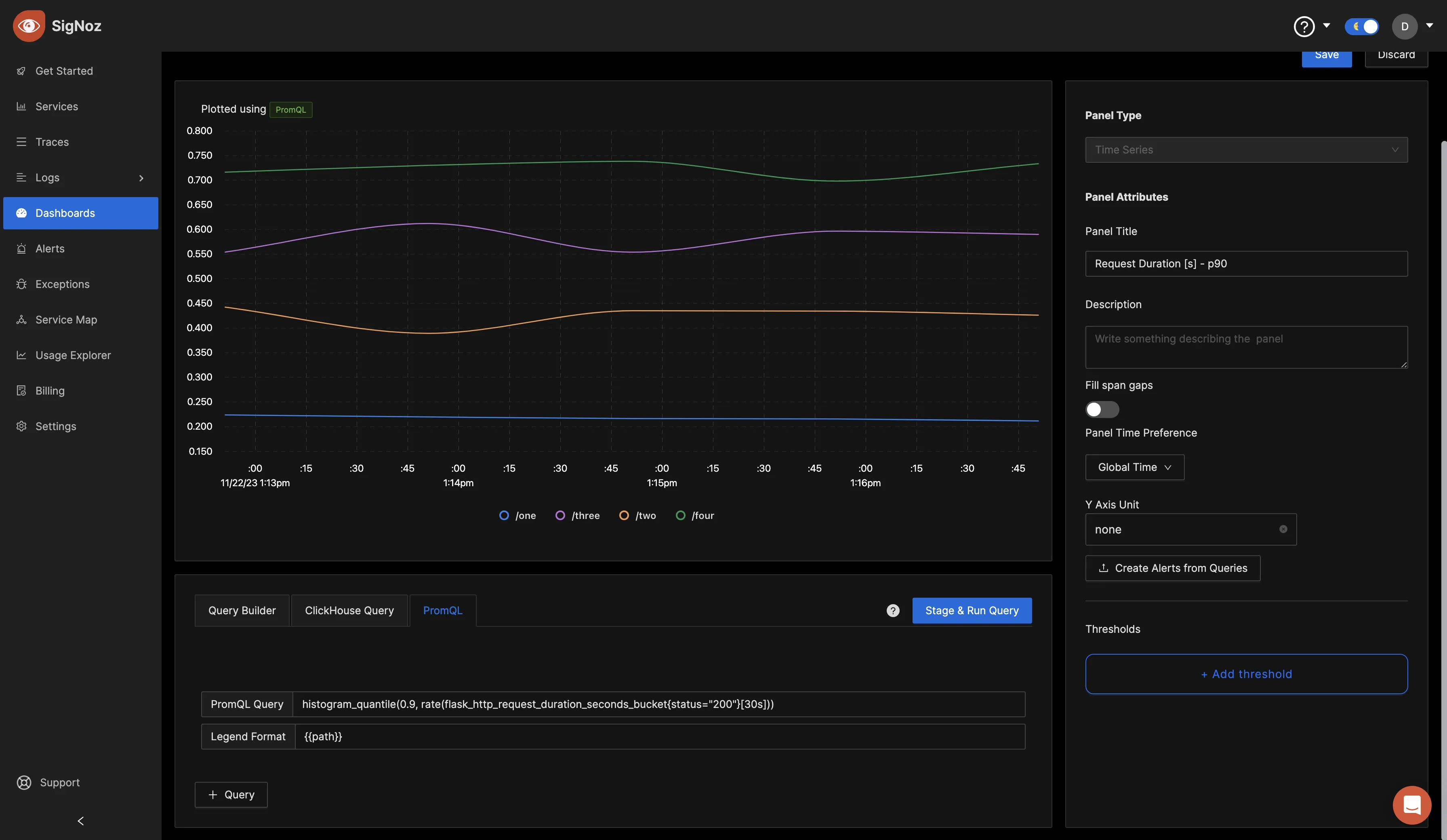
This query leverages the histogram_quantile function to determine the 90th percentile of the request duration for successful (status code 200) Flask HTTP requests over the last 30 seconds. The 'Legend Format' helps label the data points with the corresponding path information.
Click on the "Stage and Run Query" button, and then save the panel.
You can repeat the same steps for different metrics you would like to visualize. After creating different panels for various metrics, click on the "Save Layout" button, which enables you to save the current arrangement and configuration of your panels. This ensures that your customized dashboard layout and visualizations are saved for future reference and monitoring.
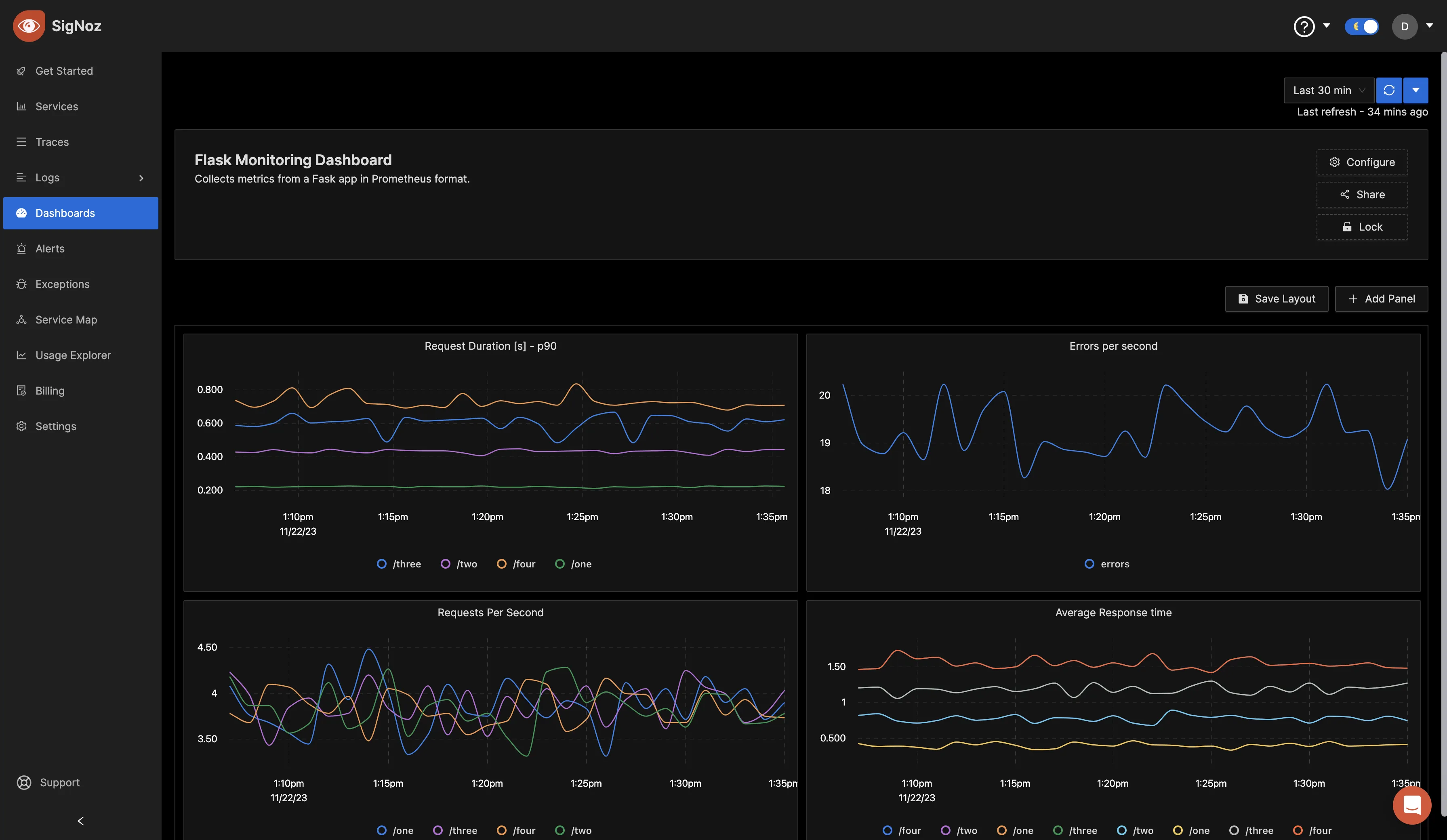
If you would like to replicate the above dashboard, you can easily do so by copying the JSON file available in this GitHub repo. Import the copied JSON file into a new dashboard, and it will recreate the same layout and configurations for your convenience.
Conclusion
In this tutorial, you configured an OpenTelemetry collector to scrape Prometheus metrics from a sample flask application. You then sent the data to SigNoz for monitoring and visualization.
Visit our complete guide on OpenTelemetry Collector to learn more about it.
OpenTelemetry is becoming a global standard for open-source observability, offering advantages such as a unified standard for all telemetry signals and avoiding vendor lock-in. With OpenTelemetry, instrumenting your applications to collect logs, metrics, and traces becomes seamless, and you can monitor and visualize your telemetry data with SigNoz.
As SigNoz is a full-stack observability tool, you don't have to use multiple tools for your monitoring needs.
Further Reading
Complete Guide on OpenTelemetry Collector

